SelfHostLLM
Calculate the GPU memory you need for LLM inference
2025-08-08
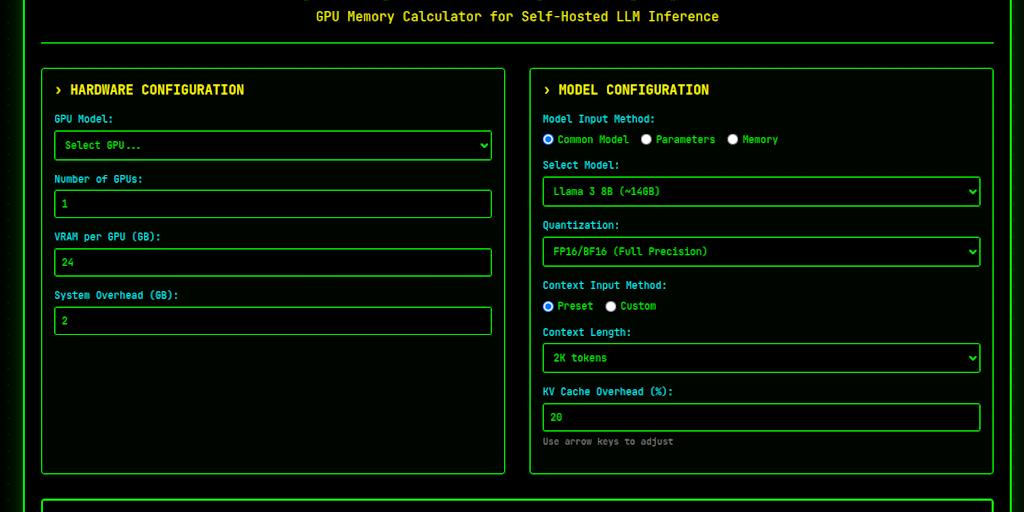
Calculate GPU memory requirements and max concurrent requests for self-hosted LLM inference. Support for Llama, Qwen, DeepSeek, Mistral and more. Plan your AI infrastructure efficiently.
SelfHostLLM helps users efficiently plan their AI infrastructure by calculating GPU memory requirements and maximum concurrent requests for self-hosted LLM inference. It supports popular models like Llama, Qwen, DeepSeek, and Mistral.
The tool breaks down the calculation into clear steps: determining total VRAM, adjusting for quantization, estimating KV cache per request, and subtracting system overhead. This provides a realistic estimate of available memory for inference. Results indicate serving capability, from personal use to small-scale deployment or production-ready setups.
Key considerations include model architecture, actual token usage, and attention mechanisms. While the tool offers a rough estimate, real-world performance may vary due to framework overhead and dynamic batching optimizations. Ideal for optimizing GPU resource allocation.
The tool breaks down the calculation into clear steps: determining total VRAM, adjusting for quantization, estimating KV cache per request, and subtracting system overhead. This provides a realistic estimate of available memory for inference. Results indicate serving capability, from personal use to small-scale deployment or production-ready setups.
Key considerations include model architecture, actual token usage, and attention mechanisms. While the tool offers a rough estimate, real-world performance may vary due to framework overhead and dynamic batching optimizations. Ideal for optimizing GPU resource allocation.
Open Source
Developer Tools
Artificial Intelligence
GitHub