SelfHostLLM
计算进行LLM推理所需的GPU内存
2025-08-08
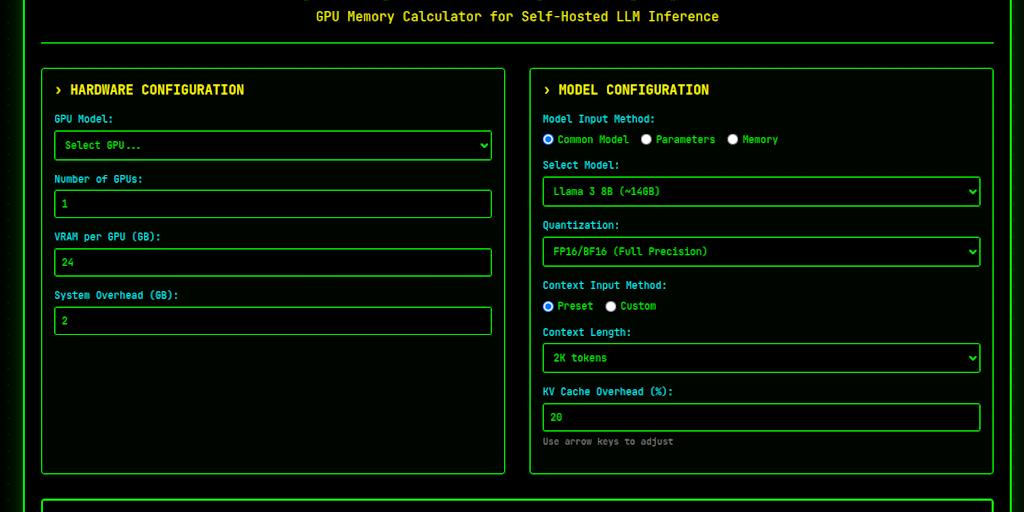
计算自托管LLM推理所需的GPU内存和最大并发请求数。支持Llama、Qwen、DeepSeek、Mistral等模型。高效规划您的AI基础设施。
SelfHostLLM通过计算自托管LLM推理所需的GPU内存和最大并发请求数,帮助用户高效规划其AI基础设施。它支持Llama、Qwen、DeepSeek和Mistral等流行模型。
该工具将计算分解为清晰的步骤:确定总VRAM、量化调整、估计每个请求的KV缓存,并减去系统开销。这为推理提供了可用内存的现实估计。结果表明了服务能力,从个人使用到小规模部署或生产就绪的设置。
关键考虑因素包括模型架构、实际令牌使用情况和注意力机制。虽然该工具提供了一个粗略的估计,但由于框架开销和动态批处理优化,实际性能可能会有所不同。非常适合优化GPU资源分配。
该工具将计算分解为清晰的步骤:确定总VRAM、量化调整、估计每个请求的KV缓存,并减去系统开销。这为推理提供了可用内存的现实估计。结果表明了服务能力,从个人使用到小规模部署或生产就绪的设置。
关键考虑因素包括模型架构、实际令牌使用情况和注意力机制。虽然该工具提供了一个粗略的估计,但由于框架开销和动态批处理优化,实际性能可能会有所不同。非常适合优化GPU资源分配。
Open Source
Developer Tools
Artificial Intelligence
GitHub