SmolDocling
256M VLM for end-to-end document AI
2025-03-25
SmolDocling, from Hugging Face and IBM Research, is the ultra-compact (256M) open VLM for end-to-end document conversion. Extracts text, layout, tables, code, and more from images.
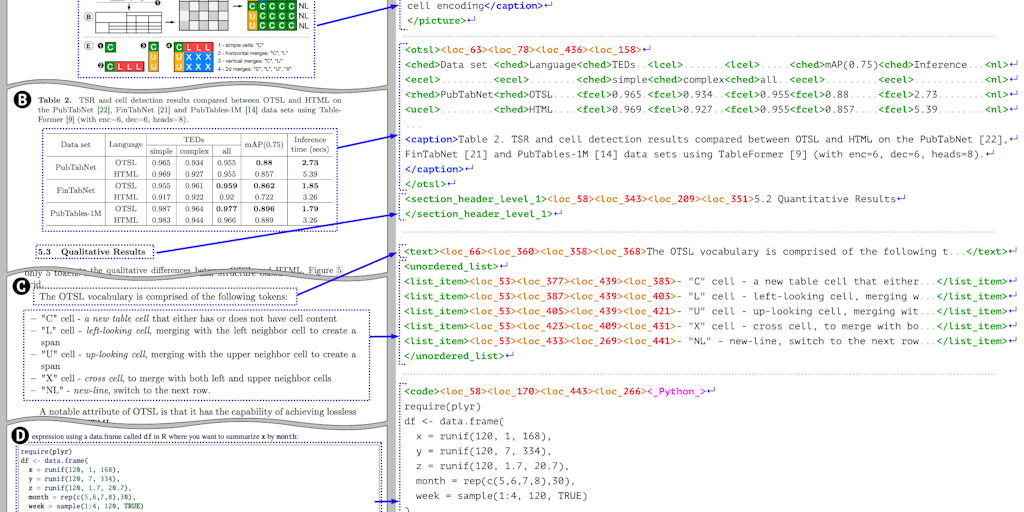
SmolDocling is an ultra-compact, open-source vision-language model (256M parameters) developed by Hugging Face and IBM Research for efficient document conversion. It extracts text, layout, tables, code, and other elements from images, enabling seamless transformation into formats like markdown, HTML, and more. Compatible with popular inference tools like Transformers, vLLM, and ONNX, it supports DoclingDocuments for flexible output generation. Designed for multimodal image-to-text processing, SmolDocling retains key features of its predecessor while optimizing for size and speed. Users can perform local inference or leverage GPU acceleration for tasks such as OCR, table extraction, and LaTeX conversion. The model is documented in an arXiv paper, with a demo available on Hugging Face Spaces. Its lightweight architecture makes it ideal for scalable document AI applications. For developers, SmolDocling offers straightforward integration via Python, with examples provided for different inference methods. It supports specialized conversions, including charts to tables and formulas to LaTeX, enhancing its utility for diverse document workflows.
Open Source
Artificial Intelligence
Development