Kyutai TTS
The voice for your real-time AI applications
2025-07-06
Kyutai TTS is a new open-source text-to-speech model optimized for real-time use. It's the first TTS that streams text in as it streams audio out, enabling ultra-low latency for LLM applications.
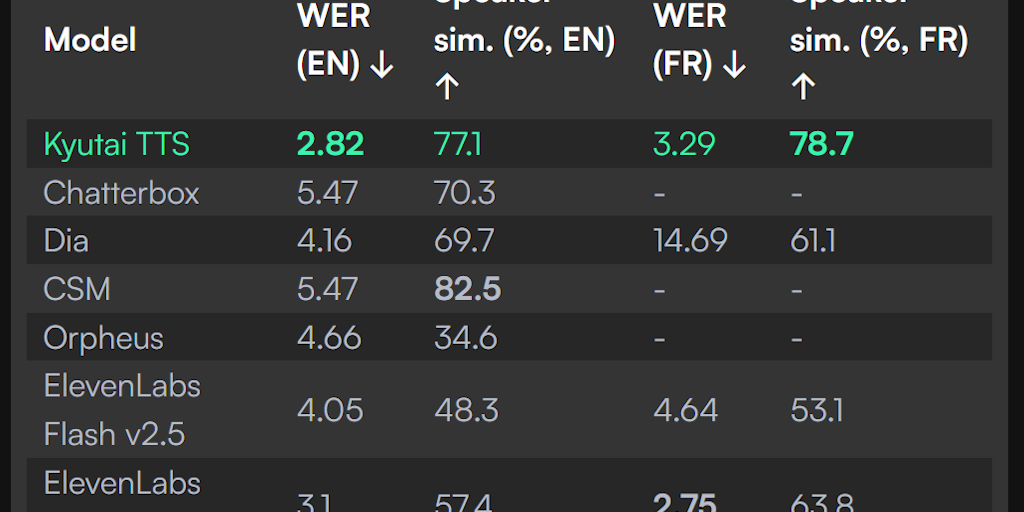
Kyutai TTS is an open-source text-to-speech model designed for real-time applications, offering ultra-low latency by processing text and audio streams simultaneously. Unlike traditional models requiring full text upfront, Kyutai TTS starts generating audio as soon as it receives the first text tokens, making it ideal for LLM integrations, especially in low-resource or long-text scenarios. The model supports English and French, delivering high accuracy with a low word error rate (2.82 EN, 3.29 FR) and strong speaker similarity (77.1% EN, 78.7% FR). It includes voice cloning from short samples and outputs word timestamps for real-time subtitles or interruption handling. Built with delayed streams modeling, Kyutai TTS enables scalable deployment, handling up to 32 simultaneous requests with a Rust-based server. Its innovative approach sets a new benchmark for real-time TTS performance.
Artificial Intelligence
Audio
Development